
reference from (https://github.com/imarvinle/interview-1#cc)
关键字以及影响
const
1.const 修饰变量/指针/常量引用/成员函数
| 类型 | 作用 |
|---|---|
| 修饰变量 | 该变量不可被修改 |
| 修饰指针+指针常量 | 常量 |
| 修饰指针+常量指针 | 同1 |
| 修饰引用 | 避免copy和对值的修改(预编译前查看) |
| 修饰成员函数 | 不允许修改成员变量(预编译前查看) |
2.static
先来复习一下进程的分区
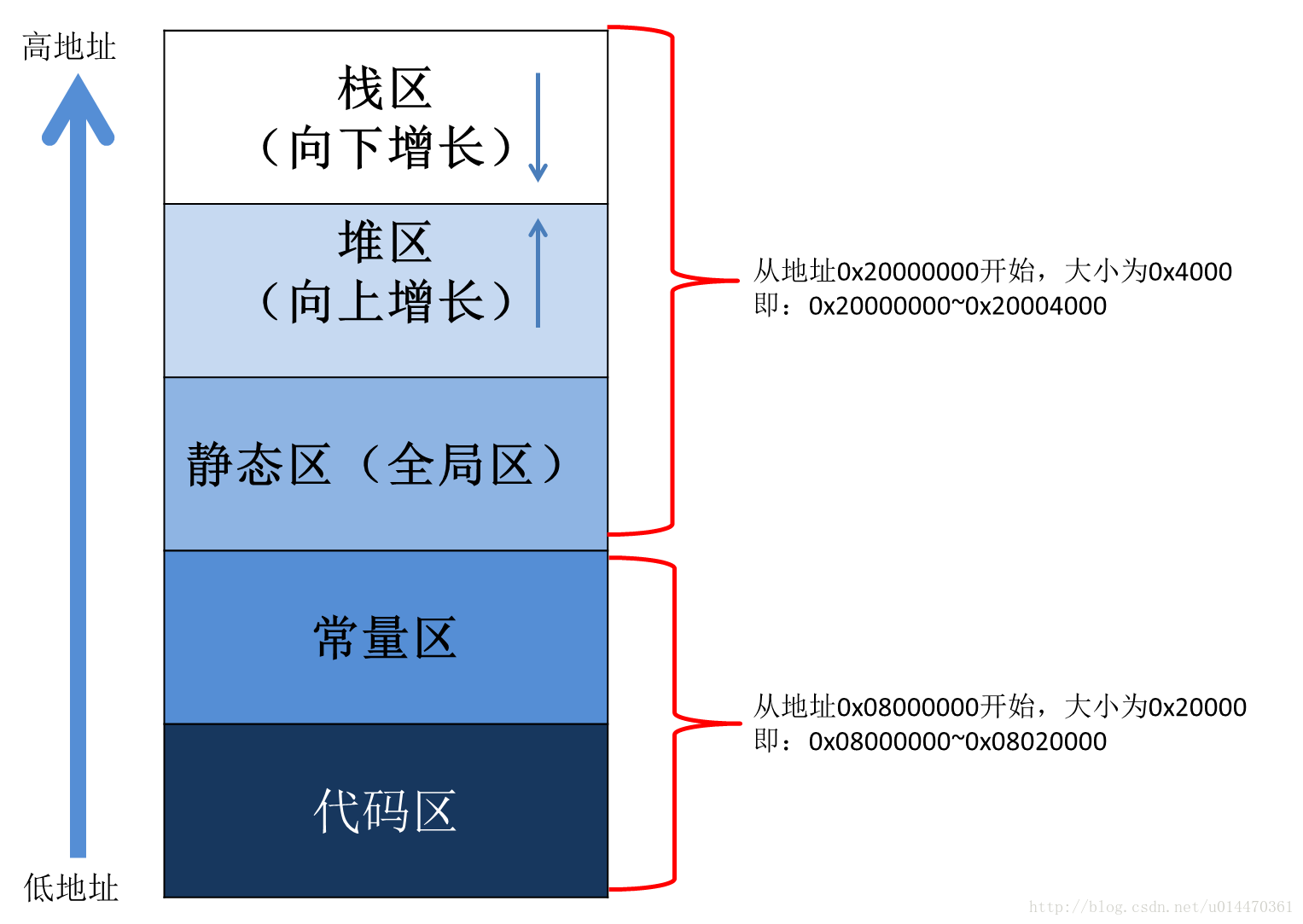
| 类型 | 作用 | 对应操作 |
|---|---|---|
| 修饰普通变量 | 该变量放置在静态区 | 在main函数前分配空间并用对应值初始化 |
| 修饰普通函数 | 该函数仅在对应文件内可用 | 防止多人开发时函数重名 |
| 修饰成员变量 | 所有成员共享一个对应变量 | 必须在类外初始化 |
| 修饰成员函数 | 不需要对象就可以访问该函数 | 在static函数内无法访问非静态成员 |
3.this指针
1.this不是一个常规变量,不能取得this的地址,存在栈上
4.inline
clang -emit-llvm -S inline_test.cpp -o inline_test.ll
1.相当于LLVM中间层里的inline操作,直接把对应函数的函数体粘贴到调用的地方
2.和宏相比,多了类型检查
3.不能包含循环/递归/switch(亲测C20已经可以switch,递归,循环了)
4.在类声明中定义的函数,除了虚函数的其他函数都会自动隐式地当成内联函数。
编译器对 inline 函数的处理步骤
1.将 inline 函数体复制到 inline 函数调用点处;
2.为所用 inline 函数中的局部变量分配内存空间;
3.将 inline 函数的的输入参数和返回值映射到调用方法的局部变量空间中;
4.如果 inline 函数有多个返回点,将其转变为 inline 函数代码块末尾的分支(使用 GOTO)。
优缺点
优点
1.内联函数同宏函数一样将在被调用处进行代码展开,省去了参数压栈、栈帧开辟与回收,结果返回等,从而提高程序运行速度。
2.内联函数相比宏函数来说,在代码展开时,会做安全检查或自动类型转换(同普通函数),而宏定义则不会。
3.在类中声明同时定义的成员函数,自动转化为内联函数,因此内联函数可以访问类的成员变量,宏定义则不能。
4.内联函数在运行时可调试,而宏定义不可以。
缺点
1.代码膨胀。内联是以代码膨胀(复制)为代价,消除函数调用带来的开销。如果执行函数体内代码的时间,相比于函数调用的开销较大,那么效率的收获会很少。另一方面,每一处内联函数的调用都要复制代码,将使程序的总代码量增大,消耗更多的内存空间。
2.inline 函数无法随着函数库升级而升级。inline函数的改变需要重新编译,不像 non-inline 可以直接链接。
3.是否内联,程序员不可控。内联函数只是对编译器的建议,是否对函数内联,决定权在于编译器。
$Q:虚函数可以是inline吗$
A:
1.虚函数可以是内联函数,内联是可以修饰虚函数的,但是当虚函数表现多态性的时候不能内联。
2.内联是在编译器建议编译器内联,而虚函数的多态性在运行期,编译器无法知道运行期调用哪个代码,因此虚函数表现为多态性时(运行期)不可以内联。
3.inline virtual 唯一可以内联的时候是:编译器知道所调用的对象是哪个类(如 Base::who()),这只有在编译器具有实际对象而不是对象的指针或引用时才会发生。
5. sizeof
返回字节数
char:1
int:4
汉字:3
6. volatile
表示不允许编译器对该变量进行寄存器优化,每次必须从内存取出值
const 可以是 volatile (如只读的状态寄存器)
指针可以是 volatile
7. extern “C”
extern “C” 的作用是让 C++ 编译器将 extern “C” 声明的代码当作 C 语言代码处理,可以避免 C++ 因符号修饰导致代码不能和C语言库中的符号进行链接的问题。
#ifdef __cplusplus
extern "C" {
#endif
void *memset(void *, int, size_t);
#ifdef __cplusplus
}
#endif
8. struct 和 class
总的来说,struct 更适合看成是一个数据结构的实现体,class 更适合看成是一个对象的实现体。
最本质的一个区别就是默认的访问控制
1.默认的继承访问权限。struct 是 public 的,class 是 private 的。
2.struct 作为数据结构的实现体,它默认的数据访问控制是 public 的,而 class 作为对象的实现体,它默认的成员变量访问控制是 private 的。
9.union
1.匿名 union 在定义所在作用域可直接访问 union 成员
2.匿名 union 不能包含 protected 成员或 private 成员
3.全局匿名联合必须是静态(static)的
#include <bits/stdc++.h>
using namespace std;
template<typename T>
union bits{
T value;
bitset<sizeof(T)*8>bit;
bits(T v):value(v){}
};
int main(){
ios::sync_with_stdio(false);
cin.tie(nullptr);
bits<int>test(4);
cout<<test.bit<<'\n';
bits<double>double_test(3.5);
cout<<double_test.bit<<'\n';//IEEE shit
return 0;
}
10. explicit
用来取消构造函数的调用
#include <iostream>
using namespace std;
class EXP_TEST{
public:
EXP_TEST(int x){
cout<<"used"<<endl;
}
};
static void test(EXP_TEST a){
}
int main( ){
test(1);
return 0;
}
11. friend
能够在别的类中对私有成员进行访问
友元关系不具有传递性
class friend_B{
friend_A a;
public:
void modify(){
a.wallet++;//could access
}
};
class friend_A{
friend class friend_B;
private:
int wallet;
};
12. using和::
1.全局作用域符(::name):用于类型名称(类、类成员、成员函数、变量等)前,表示作用域为全局命名空间
2.类作用域符(class::name):用于表示指定类型的作用域范围是具体某个类的
3.命名空间作用域符(namespace::name):用于表示指定类型的作用域范围是具体某个命名空间的
13. decltype
int a;
decltype(a) b;
b=1;
cout<<b<<'\n';
auto cmp=[&](int a,int b){
return a>b;
};
priority_queue<int,vector<int>,decltype(cmp)>q(cmp);//let others to deduce the answer
q.push(1);
q.push(2);
while(!q.empty()){
cout<<q.top()<<' ';
q.pop();
}
14. 引用
1.左值引用可以绑定到左值,不可以绑定到右值
2.左值常引用可以绑定到右值,此时右值在栈上
3.右值引用&&,可以指向右值,不可以指向左值,用处是可以修改右值
右值引用有以下两个好处
右值引用就是必须绑定到右值(一个临时对象、将要销毁的对象)的引用,一般表示对象的值。
1.右值引用可实现转移语义(Move Sementics)和精确传递(Perfect Forwarding),它的主要目的有两个方面:
2.消除两个对象交互时不必要的对象拷贝,节省运算存储资源,提高效率。
能够更简洁明确地定义泛型函数。
15.initializer_list
template<typename T>
struct S{
vector<T>v;
S(std::initializer_list<T> l):v(l){
cout<<"initialized "<<l.size()<<" elements\n";
}
void append(initializer_list<T> app){
v.insert(app.begin(),app.end(),v.end());
}
pair<const T*,size_t>size(){
return {&v[0],v.size()};
}
};
template<typename T>
void test(T){}
int main(){
auto li={1,3,2};//if use auto, it becomes an initializer_list
S<int> vec={1,3,2};//could not use if S is explicit
S<int>s=li;
cout<<s.size().second<<'\n';
test<initializer_list<int>>(li);
return 0;
}
16.面向对象OOP
继承,封装,多台
1.继承
父->子
2.多态
1.多态,即多种状态,在面向对象语言中,接口的多种不同的实现方式即为多态。
2.C++ 多态有两种:静态多态(早绑定)、动态多态(晚绑定)。静态多态是通过函数重载实现的;动态多态是通过虚函数实现的。
3.多态是以封装和继承为基础的。
虚函数
1.普通函数(非类成员函数)不能是虚函数
2.静态函数(static)不能是虚函数
3.构造函数不能是虚函数(因为在调用构造函数时,虚表指针并没有在对象的内存空间中,必须要构造函数调用完成后才会形成虚表指针)
4.内联函数不能是表现多态性时的虚函数,解释见:虚函数(virtual)可以是内联函数(inline)吗?
虚函数和纯虚函数
1.类里如果声明了虚函数,这个函数是实现的,哪怕是空实现,它的作用就是为了能让这个函数在它的子类里面可以被覆盖,这样的话,这样编译器就可以使用后期绑定来达到多态了。纯虚函数只是一个接口,是个函数的声明而已,它要留到子类里去实现。
2.虚函数在子类里面也可以不重载的;但纯虚函数必须在子类去实现。
3.虚函数的类用于 “实作继承”,继承接口的同时也继承了父类的实现。当然大家也可以完成自己的实现。纯虚函数关注的是接口的统一性,实现由子类完成。
4.带纯虚函数的类叫抽象类,这种类不能直接生成对象,而只有被继承,并重写其虚函数后,才能使用。抽象类和大家口头常说的虚基类还是有区别的,在 C# 中用 abstract 定义抽象类,而在 C++ 中有抽象类的概念,但是没有这个关键字。抽象类被继承后,子类可以继续是抽象类,也可以是普通类,而虚基类,是含有纯虚函数的类,它如果被继承,那么子类就必须实现虚基类里面的所有纯虚函数,其子类不能是抽象类。
虚函数指针:在含有虚函数类的对象中,指向虚函数表,在运行时确定。
虚函数表:在程序只读数据段(.rodata section,见:目标文件存储结构),存放虚函数指针,如果派生类实现了基类的某个虚函数,则在虚表中覆盖原本基类的那个虚函数指针,在编译时根据类的声明创建。
虚继承
针对菱形继承
如果一个变量在A中有,那么当D想要去修改的话。该变量可能来自于B也可能来自于C,这个时候就有歧义了
class A{
protected:
int m_a;
};
//直接基类B
class B: virtual public A{ //虚继承
protected:
int m_b;
};
//直接基类C
class C: virtual public A{ //虚继承
protected:
int m_c;
};
//派生类D
class D: public B, public C{
public:
void seta(int a){ m_a = a; } //正确
void setb(int b){ m_b = b; } //正确
void setc(int c){ m_c = c; } //正确
void setd(int d){ m_d = d; } //正确
private:
int m_d;
};
int main(){
D d;
return 0;
}
虚继承的目的是让某个类做出声明,承诺愿意共享它的基类。其中,这个被共享的基类就称为虚基类(Virtual Base Class),本例中的 A 就是一个虚基类。在这种机制下,不论虚基类在继承体系中出现了多少次,在派生类中都只包含一份虚基类的成员。
抽象类、接口类、聚合类
1.抽象类:含有纯虚函数的类
2.接口类:仅含有纯虚函数的抽象类
3.聚合类:用户可以直接访问其成员,并且具有特殊的初始化语法形式。满足如下特点:
a.所有成员都是 public
b.没有有定于任何构造函数
c.没有类内初始化
d.没有基类,也没有 virtual 函数
17.malloc free
首先对于内存分配来说,有静态分配和动态分配,静态分配的内存在栈上,动态分配的内存在堆上
malloc用于动态分配
在底层,malloc主要调用了mmap和brk
mmap主要采用了其匿名映射,在虚存中开辟一块区域
brk用于修改映射大小
对于malloc来说,帮你完成了内存管理,总有一个指针指向当前可用的区域
malloc用chunk做管理,在每个可用指针前,总有一个当前chunk的大小的值存着
这个内存区域的最后一位代表该chunk是否使用,为1就是使用了
对于free来说,free会使用内存块本来的空间来把自身加入到双向链表当中去
18. malloc、calloc、realloc、alloca
1.malloc:申请指定字节数的内存。申请到的内存中的初始值不确定。
2.calloc:为指定长度的对象,分配能容纳其指定个数的内存。申请到的内存的每一位(bit)都初始化为 0。
3.realloc:更改以前分配的内存长度(增加或减少)。当增加长度时,可能需将以前分配区的内容移到另一个足够大的区域,而新增区域内的初始值则不确定。
4.alloca:在栈上申请内存。程序在出栈的时候,会自动释放内存。但是需要注意的是,alloca 不具可移植性, 而且在没有传统堆栈的机器上很难实现。alloca 不宜使用在必须广泛移植的程序中。C99 中支持变长数组 (VLA),可以用来替代 alloca。
19. new delete
1.new / new[]:完成两件事,先底层调用 malloc 分了配内存,然后调用构造函数(创建对象)。
2.delete/delete[]:也完成两件事,先调用析构函数(清理资源),然后底层调用 free 释放空间。
3.new 在申请内存时会自动计算所需字节数,而 malloc 则需我们自己输入申请内存空间的字节数。
20. 是否能delete this
1.可以,但是需要保证对象是分配在堆上的
2.最后一个用的
21.如何定义一个只能在堆/栈上生成对象的类?
1.只能在堆上
方法:将析构函数设置为私有
原因:C++ 是静态绑定语言,编译器管理栈上对象的生命周期,编译器在为类对象分配栈空间时,会先检查类的析构函数的访问性。若析构函数不可访问,则不能在栈上创建对象。
2.只能在栈上
方法:将 new 和 delete 重载为私有
原因:在堆上生成对象,使用 new 关键词操作,其过程分为两阶段:第一阶段,使用 new 在堆上寻找可用内存,分配给对象;第二阶段,调用构造函数生成对象。将 new 操作设置为私有,那么第一阶段就无法完成,就不能够在堆上生成对象。
22. =delete
声明为=delete之后就不允许对应的隐式转换了
#include <bits/stdc++.h>
using namespace std;
void print(double a)=delete;
void print(int a){
cout<<a<<'\n';
}
int main(){
print(1);
return 0;
}
23. 继承
| public | protected | private | |
|---|---|---|---|
| 公有继承 | public | protected | 不可见 |
| 私有继承 | private | private | 不可见 |
| 保护继承 | protected | protected | 不可见 |
24.虚函数表
1.虚表是一个指针数组,其元素是虚函数的指针,每个元素对应一个虚函数的函数指针。需要指出的是,普通的函数即非虚函数,其调用并不需要经过虚表,所以虚表的元素并不包括普通函数的函数指针。
2.虚表内的条目,即虚函数指针的赋值发生在编译器的编译阶段,也就是说在代码的编译阶段,虚表就可以构造出来了。
虚函数表放在类对象的最前面
25.delete和delete []
auto arr[]
delete arr:调用 arr[0]的析构函数
delete arr[] 分别调用arr每一个元素的析构函数
26.i++和++i谁快
++i快
++i相当于
i = i + 1 ;
return i;
i++相当于
int j = i;
i = i + 1 ;
return j;
27.override
override 关键字可以放在子类中重写父类的虚函数声明的末尾,用于显式地声明该函数是对父类虚函数的重写,从而告诉编译器进行检查。如果子类中的函数与父类中的函数不完全一致,编译器会在编译时报错,从而避免了潜在的错误。如果子类中的函数与父类中的函数完全一致,那么 override 关键字不会对程序的运行产生任何影响。
28.构造函数里能调用虚函数吗
可以。
在对象构造过程中,先调用基类构造函数,然后再调用派生类构造函数。当基类的构造函数调用虚函数时,由于此时派生类尚未构造完毕,因此实际调用的是基类的虚函数。这可能导致一些未定义的行为或者出现问题。
因此,建议在构造函数中避免调用虚函数,或者将虚函数设置为纯虚函数,这样在编译时就会报错,避免出现运行时错误。如果确实需要在构造函数中调用虚函数,可以使用普通函数替代,或者将虚函数调用延迟到对象构造完毕后再进行。
29.哪些变量存在栈上,哪些存在堆上
| 位置 | 常见变量 |
|---|---|
| 栈 | 1.函数内的自动变量(int a=10;)2.函数参数。3.局部对象 |
| 堆 | new 或者malloc出来的对象 |
30.多线程访问静态变量需要加锁
31.
char * c="abcd"
c不能更改,在常量区
32.链接方式
1.静态链接:在程序运行前,先将各个目标模块以及他们所需的库函数连接成一个完成的可执行文件,之后不再拆开;
2.装入时动态链接:将各目标模块装入内存时,边装入边链接。
3.运行时动态链接:在程序执行中需要该目标模块时,才对它进行链接。优点是便于修改和更新,便于实现对目标的共享。->dll
装入:可执行文件只有被装载到内存以后才能被CPU执行,由装入程序Loader将装入模块装入内存运行. 有三种装入方式:
1.绝对装入:在编译时,如果知道程序将放到内存中的哪个位置,编译程序将产生绝对地址的目标代码。即编译、链接后得到的装入模块的指令直接就使用了绝对地址;装入程序按照装入模块中的地址,将程序和数据装入内存;绝对装入只适用于单道程序环境。
2.静态重定位(可重定位装入):编译、链接后的装入模块的地址都是从0开始的,指令中使用的地址、数据存放的地址都是相对于起始地址而言的逻辑地址,装入程序根据内存的当前情况,将装入模块装入到内存的适当位置,并在装入时对地址进行重定位,将逻辑地址变换为物理地址。地址变换是在装入时一次性完成的。
特点:静态重定位的特点是在一个作业装入内存时,必须分配其要求的全部内存空间,如果没有足够的内存,则装入失败。作业一旦进入内存后,运行期间不能再移动,也不能再申请新的内存空间。
3.动态重定位(动态运行时装入):编译、链接后的装入模块的地址都是从0开始的,装入程序把装入模块装入内存后,在程序真正执行时候进行地址转换。因此装入内后后所有地址依然是逻辑地址。这种方式需要一个重定位寄存器(存放装入模块存放的起始位置)的支持。采用动态重定位时允许程序在内存中发生移动。
特点:并且可将程序分配到不连续的内存空间中;还可以只用装入部分程序代码即可运行,在程序运行时进行动态内存分配即可;便于程序段的共享,可以向用户提供一个比存储空间大得多的地址空间;
33.移动构造函数
在 C++ 中,如果需要将一个对象传递给另一个函数或者从一个函数返回一个对象,通常需要进行复制构造函数或拷贝赋值运算符操作,这会涉及到对象的拷贝和内存分配,当对象较大或者拷贝次数频繁时,这样的操作会导致程序性能下降。
例子如下
#include <iostream>
#include <cstring>
class MyString {
public:
// Default constructor
MyString() : m_Buffer(nullptr), m_Size(0) {}
// Constructor with string literal
MyString(const char* str) {
m_Size = std::strlen(str);
m_Buffer = new char[m_Size + 1];
std::strcpy(m_Buffer, str);
}
// Move constructor
MyString(MyString&& other) noexcept {
m_Buffer = other.m_Buffer;
m_Size = other.m_Size;
other.m_Buffer = nullptr;
other.m_Size = 0;
}
// Destructor
~MyString() {
if (m_Buffer != nullptr) {
delete[] m_Buffer;
}
}
// Copy constructor
MyString(const MyString& other) {
m_Size = other.m_Size;
m_Buffer = new char[m_Size + 1];
std::strcpy(m_Buffer, other.m_Buffer);
}
// Copy assignment operator
MyString& operator=(const MyString& other) {
if (this != &other) {
delete[] m_Buffer;
m_Size = other.m_Size;
m_Buffer = new char[m_Size + 1];
std::strcpy(m_Buffer, other.m_Buffer);
}
return *this;
}
// Move assignment operator
MyString& operator=(MyString&& other) noexcept {
if (this != &other) {
delete[] m_Buffer;
m_Buffer = other.m_Buffer;
m_Size = other.m_Size;
other.m_Buffer = nullptr;
other.m_Size = 0;
}
return *this;
}
// Getter for buffer size
size_t size() const {
return m_Size;
}
// Getter for buffer pointer
const char* c_str() const {
return m_Buffer;
}
private:
char* m_Buffer;
size_t m_Size;
};
int main() {
// Create a MyString object using a string literal
MyString str1("Hello, world!");
// Create another MyString object by moving str1
MyString str2(std::move(str1));
// Print the contents of str2
std::cout << "str2: " << str2.c_str() << std::endl;
return 0;
}
34.constexpr 和const
const 表示一个变量或者对象是不可修改的,即它的值在初始化之后不能被改变。它可以用于变量、函数参数、函数返回值和成员函数等。使用 const 可以确保代码的正确性和安全性,防止不必要的修改。
constexpr 表示一个表达式在编译时就可以被计算出来,并且结果可以作为常量使用。它可以用于变量、函数和类的成员函数等。使用 constexpr 可以提高代码的性能和安全性,避免在运行时进行重复的计算。
35. noexcept
noexcept 是 C++11 引入的一个关键字,表示一个函数或者表达式是否会抛出异常。当在函数或者表达式后面添加 noexcept 关键字时,意味着它不会抛出异常。如果一个函数或者表达式可能会抛出异常,我们不应该使用 noexcept 关键字。
noexcept 关键字可以用于函数的声明和定义中。函数声明后面添加 noexcept 关键字表示该函数不会抛出异常,而函数定义后面添加 noexcept 关键字表示该函数在运行时不会抛出异常。
noexcept 关键字的使用有助于提高代码的性能和安全性。由于不需要进行异常处理,函数的调用和执行速度可以更快。此外,noexcept 关键字还可以帮助编译器进行一些优化,例如移动语义和函数返回值优化等。
36.内存中子类和父类的布局
1.每个类都有虚指针和虚表;
2.如果不是虚继承,那么子类将父类的虚指针继承下来,并指向自身的虚表(发生在对象构造时)。有多少个虚函数,虚表里面的项就会有多少。多重继承时,可能存在多个的基类虚表与虚指针;
3.如果是虚继承,那么子类会有两份虚指针,一份指向自己的虚表,另一份指向虚基表,多重继承时虚基表与虚基表指针有且只有一份。